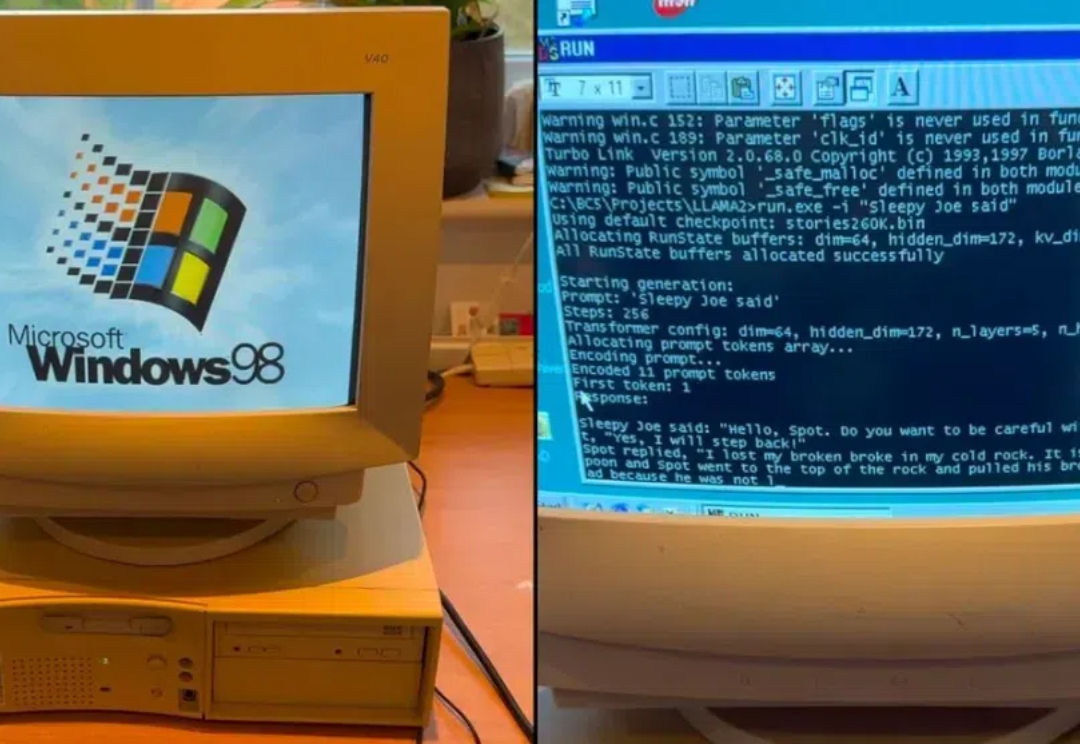
26年前老年机跑Llama2,每秒39个token:你的AI PC,也可以是Windows 98
26年前老年机跑Llama2,每秒39个token:你的AI PC,也可以是Windows 98让 Llama 2 在 Windows 98 奔腾 2(Pentium II)机器上运行,不但成功了,输出达到 39.31 tok / 秒。
来自主题: AI资讯
9998 点击 2024-12-30 15:15
 搜索
搜索
让 Llama 2 在 Windows 98 奔腾 2(Pentium II)机器上运行,不但成功了,输出达到 39.31 tok / 秒。
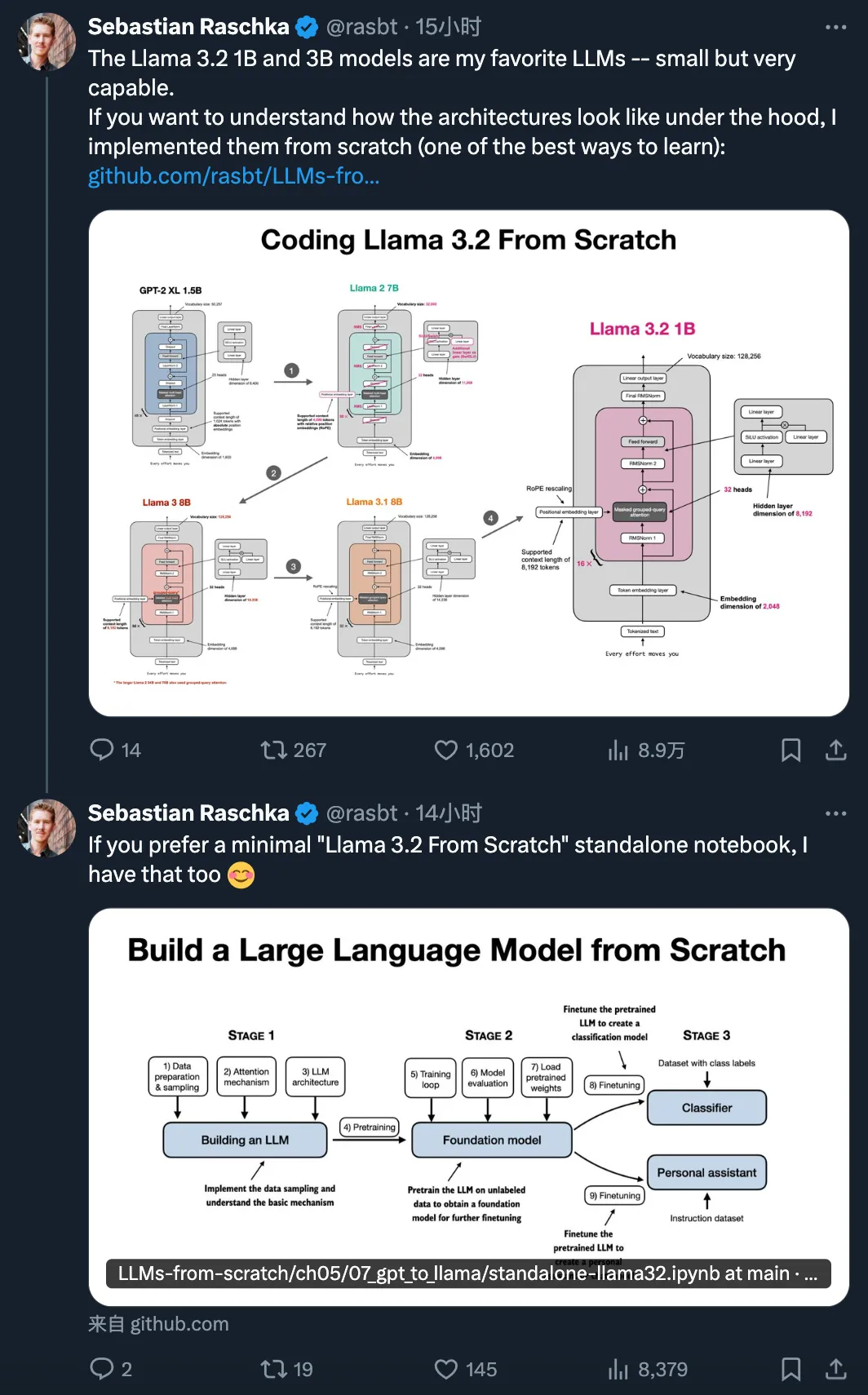
十天前的 Meta Connect 2024 大会上,开源领域迎来了可在边缘和移动设备上的运行的轻量级模型 Llama 3.2 1B 和 3B。两个版本都是纯文本模型,但也具备多语言文本生成和工具调用能力。Meta 表示,这些模型可让开发者构建个性化的、在设备本地上运行的通用应用 —— 这类应用将具备很强的隐私性,因为数据无需离开设备。
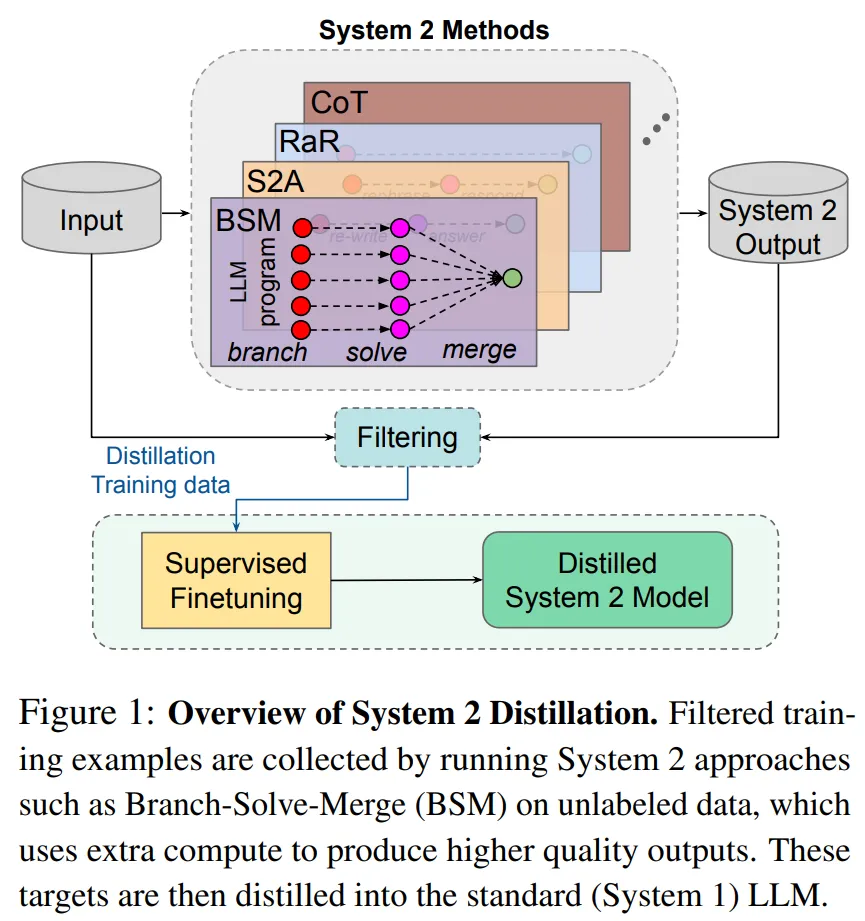
研究者表示,如果 Sytem 2 蒸馏可以成为未来持续学习 AI 系统的重要特征,则可以进一步提升 System 2 表现不那么好的推理任务的性能。

在以英语为主的语料库上训练的多语言LLM,是否使用英语作为内部语言?对此,来自EPFL的研究人员针对Llama 2家族进行了一系列实验。
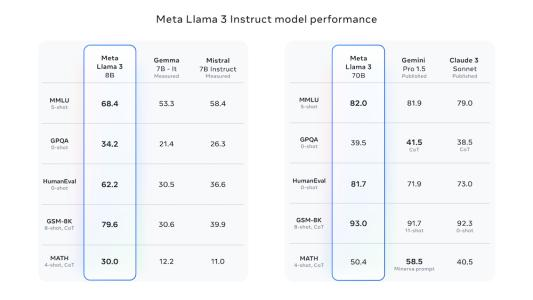
智东西4月19日消息,Meta推出迄今为止能力最强的开源大模型Llama 3系列,发布8B和70B两个版本。 Llama 3在一众榜单中取得开源SOTA(当前最优效果)。Llama 3 8B在MMLU、GPQA、HumanEval、GSM-8K等多项基准上超过谷歌Gemma 7B和Mistral 7B Instruct。

继Mamba之后,又一敢于挑战Transformer的架构诞生了!
一条磁力链,Mistral AI又来闷声不响搞事情。

Stability AI推出Stable LM 2 12B模型,作为其新模型系列的进一步升级,该模型基于七种语言的2万亿Token进行训练,拥有更多参数和更强性能,据称在某些基准下能超越Llama 2 70B。
Anthropic 发现一种新型越狱漏洞并给出了高效的缓解方案,可以将攻击成功率从 61% 降至 2%。

【新智元导读】就在刚刚,全球最强开源大模型王座易主,创业公司Databricks发布的DBRX,超越了Llama 2、Mixtral和Grok-1。MoE又立大功!这个过程只用了2个月,1000万美元,和3100块H100。